Github Link: https://github.com/rukshar69/Transformers/blob/master/rukshar_transformer_sentiment_analysis.ipynb
Here, we fine-tune a BERT Machine Learning model to build a Sentiment Classifier using Google Play app reviews dataset and the Transformers library by Hugging Face!
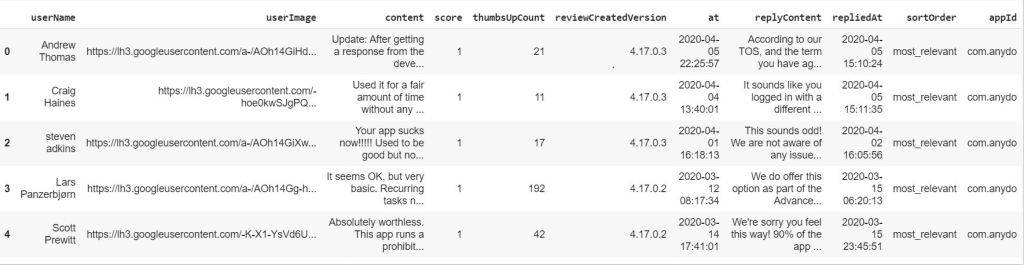
A glimpse at the dataset. Here we use the ‘content’ and the ‘score’ column for sentiment analysis. The dataset’s shape is: (15746, 11) meaning, it has nearly 16,000 samples.
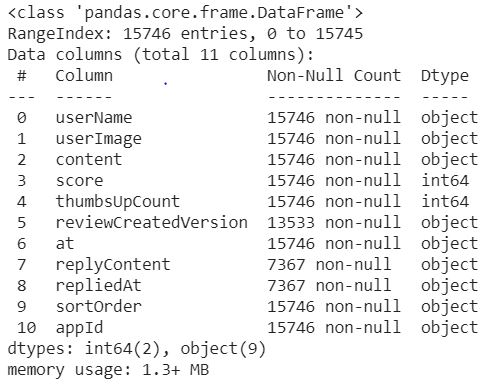
A good thing about this data is that there are no missing row values for the columns ‘content’ and ‘score’.
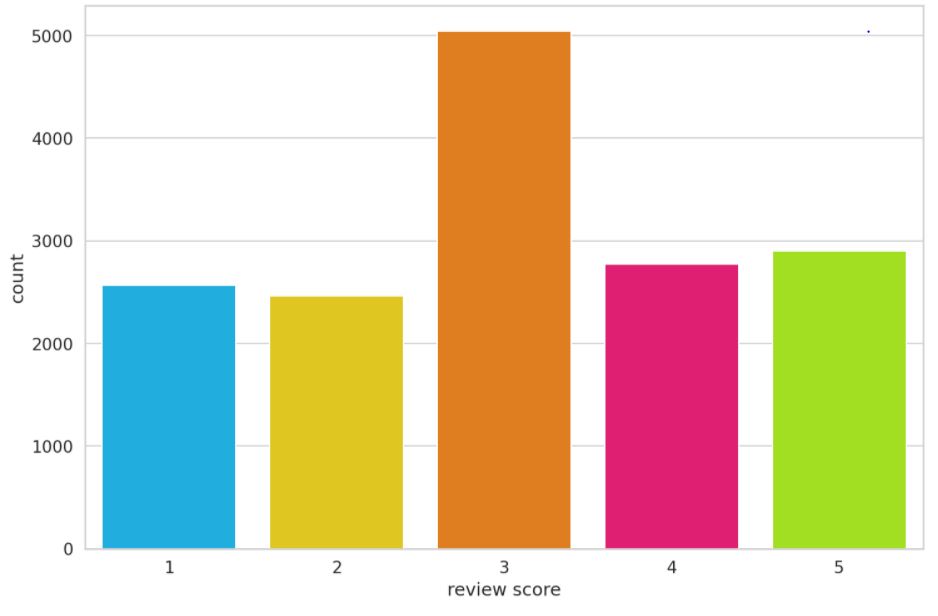
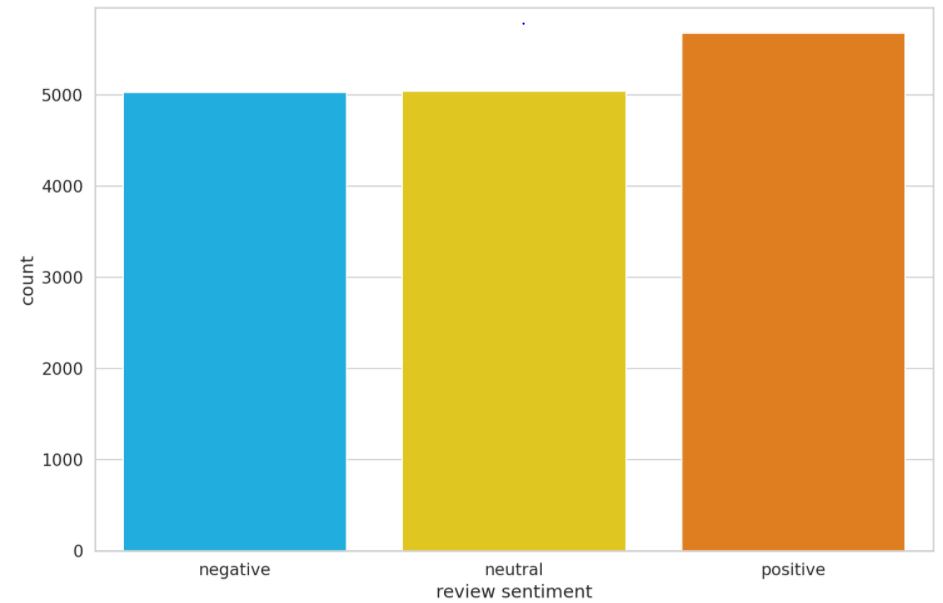
So our class labels are quite imbalanced because a lot of the rows have the score ‘3’. However, we can approximately balance the data by dividing the data into 3 classes instead of 5 classes( as in the original dataset). We combine the score 1 and 2 as ‘negative’ class, and combine the score 4 and 5 as ‘positive’ class. The socre 3 will be termed as ‘neutral’ class.
Data Preprocessing
BERT requires the following data preprocessing:
- Adding special tokens for classification
- Making sequences of constant length by introduce padding
- Making attention mask which is an array of 0s and 1s. The 0s represent pad token and the 1s represent real token.
To tokenize the data we use BERT’s pre-built tokenizer. In the code, we used ‘bert-base-cased’. There’s also an uncased version of BERT tokenizer. The cased tokenizer is better because ‘The app is BAD’ is more sentimental than ‘The app is bad’.
Before tokenizing the dataset, I’ve experimented with the tokenizer with a sample sentence. ‘When was I last outside? I am stuck at home for 2 weeks.’
The associated tokens and their respective token ids:
Tokens: [‘When’, ‘was’, ‘I’, ‘last’, ‘outside’, ‘?’, ‘I’, ‘am’, ‘stuck’, ‘at’, ‘home’, ‘for’, ‘2’, ‘weeks’, ‘.’] Token IDs: [1332, 1108, 146, 1314, 1796, 136, 146, 1821, 5342, 1120, 1313, 1111, 123, 2277, 119]
When I ran the tokenizer and the encoder on this sentence the tokenized tensor looks like the following:
tensor([ 101, 1332, 1108, 146, 1314, 1796, 136, 146, 1821, 5342, 1120, 1313, 1111, 123, 2277, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
It’s length is 32 which is the max_length attribute set in the encoding function. The 0s in the end of the tensor refers to the padding. The corresponding attention mask:
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
Here the 0s refers to the padding as well.
In order to choose the max_length attribute for the encoder of our dataset since BERT works with fixed-length sequences, we plot the number of tokens in each sample.
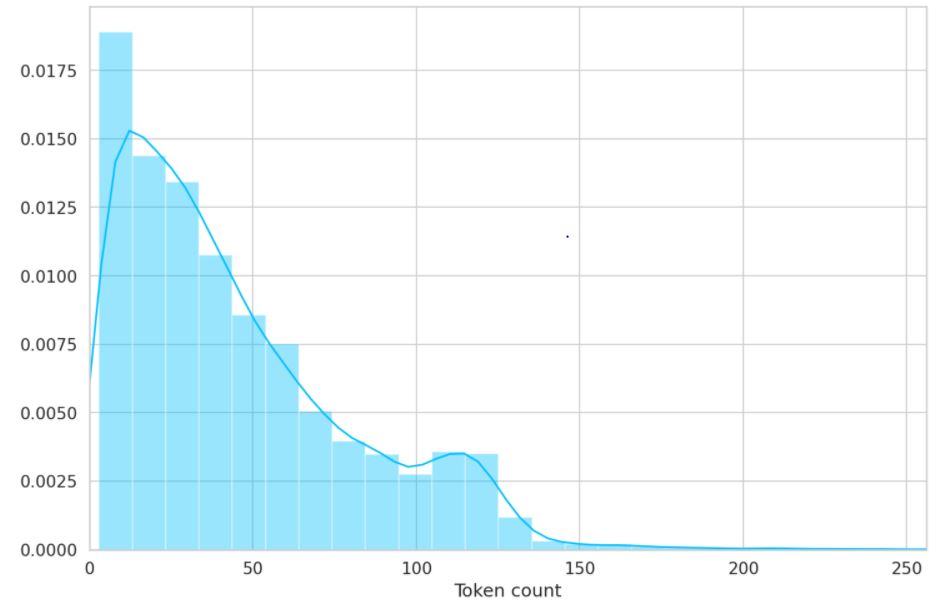
To be on the safe side, we choose a maximum length of 160 for the dataset encoder.
We now divide the data into train, validation and test sets and use the encoder to encode the data. This encoded data will then be used in our model. We reserve 90% of our data for training. 5% of the rest is for testing and the other 5% is for validation. We train the model for 10 epochs and with AdamW optimizer with learning rate of 2e-5. We’ve chosen cross-entropy for our loss function.
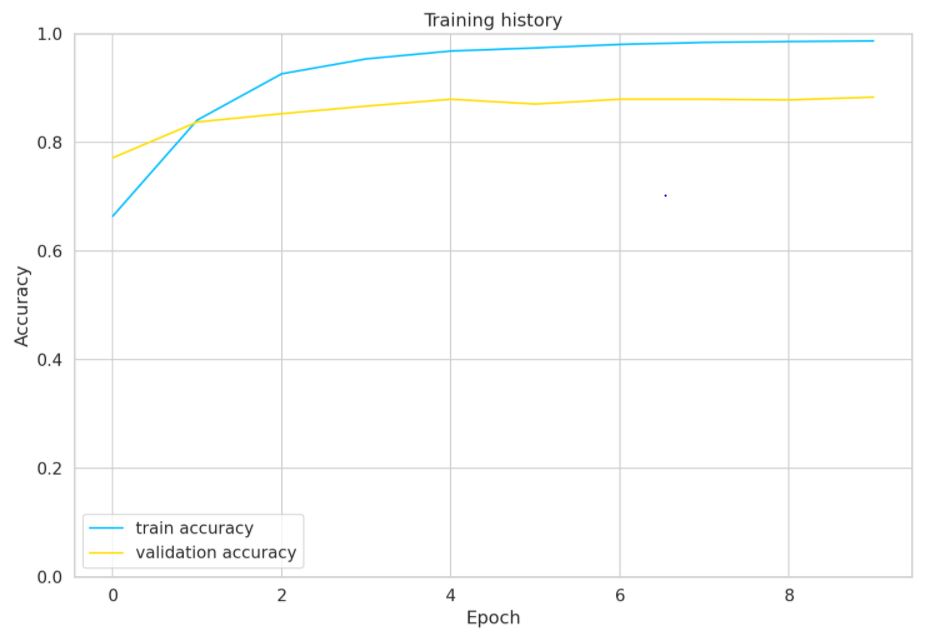
The above graph shows the Accuracy vs. Epoch of both the training and validation dataset. The accuracy on test dataset of this model is 0.8895939086294415 or nearly 89%
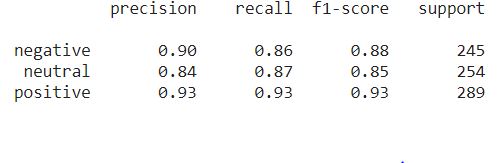
The precision, recall, and f1-score of the test dataset is given below (total rows in test set is 788):
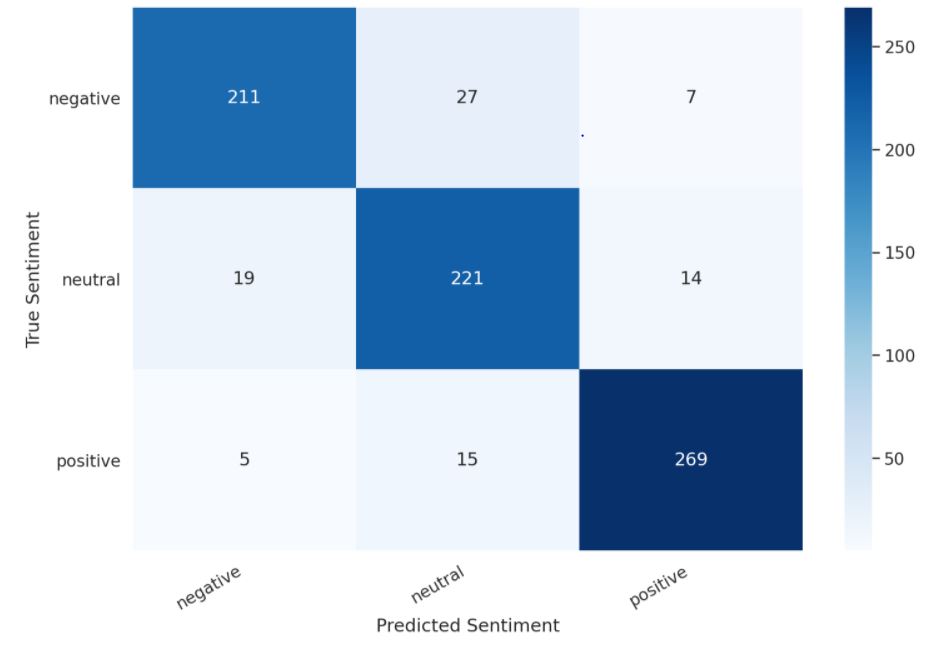
The corresponding heatmap of test dataset fed to our trained model:
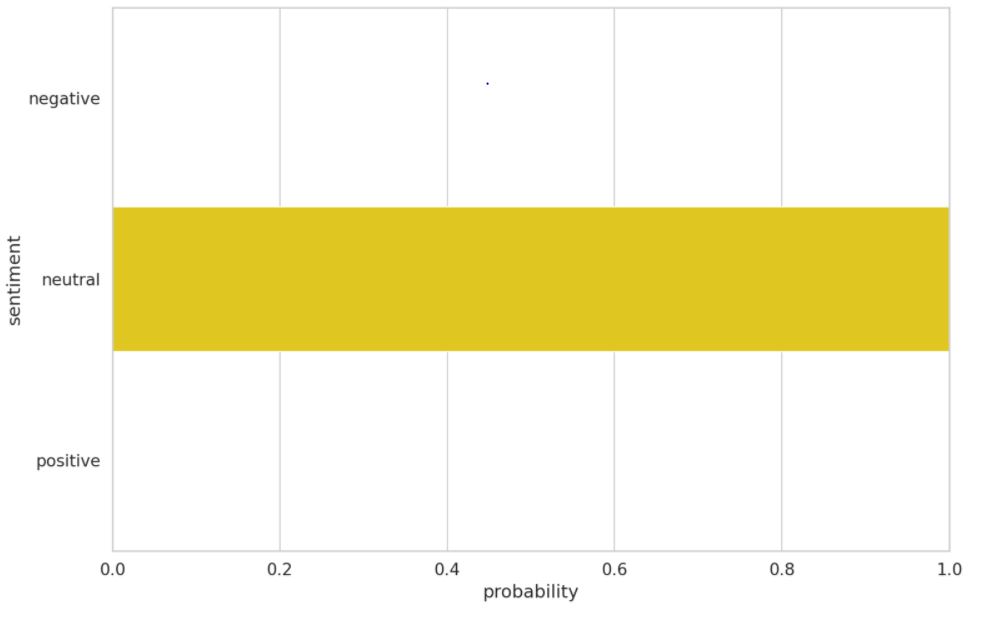
We use a test review text below to see the model’s prediction:
‘I used to use Habitica, and I must say this is a great step up. I’d like to see more social features, such as sharing tasks – only one person has to perform said task for it to be checked off, but only giving that person the experience and gold. Otherwise, the price for subscription is too steep, thus resulting in a sub-perfect score. I could easily justify $0.99/month or eternal subscription for $15. If that price could be met, as well as fine tuning, this would be easily worth 5 stars.’
The true sentiment according to the dataset is ‘neutral’
Let’s see our model’s prediction:
I now feed a made-up review and feed it to my model.
Review text: I love completing my todos! Best app ever!!!
Sentiment : positive
The output sentiment is positive.
